Io penso e il computer parla per me
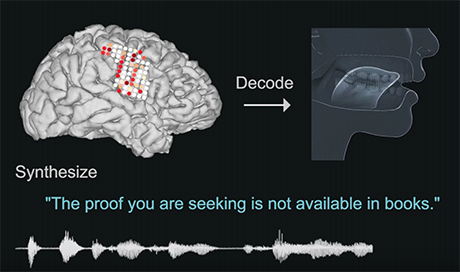
Schema dell’approccio utilizzato nella ricerca: l’attività cerebrale che controlla la fonazione viene decodificata dall’interfaccia neurale (in alto); i dati raccolti vengono elaborati per arrivare infine alla sintesi vocale (sotto) della frase pensata dal soggetto: “La prova che cerchi non si trova nei libri” (Credit: Chang lab / UCSF Dept. of Neurosurgery)
Realizzato negli Stati Uniti un dispositivo in grado di decodificare l’attività cerebrale che coordina i movimenti della fonazione e di tradurla in frasi pronunciate da un sintetizzatore vocale. Ma si tratta ancora di un prototipo che deve superare alcuni limiti tecnologici prima di essere utilizzato da chi ha perso la capacità di parlare
Un decodificatore in grado di tradurre l’attività cerebrale in linguaggio parlato potrebbe sembrare fantascienza. Invece gli studi in questa direzione stanno facendo passi da gigante, come dimostra il dispositivo descritto su “Nature” da Edward Chang e colleghi dell’Università della California a San Francisco.
Parlare è un’operazioni tra le più complesse, perché richiede una precisa coordinazione dell’attivazione di muscoli nelle strutture anatomiche che servono ad articolare i suoni, e cioè la mandibola, le labbra, la lingua e la laringe.
Per arrivare a un’interfaccia in grado di tradurre i segnali nervosi in linguaggio vocale sintetizzato da un computer, gli autori hanno adottato un approccio a due fasi, entrambe basate su reti neurali, modelli di calcolo automatico particolarmente adatti a gestire e trasformare dati che hanno una struttura temporale di elevata complessità.
La prima fase è consistita nel tradurre i segnali neurali in una sequenza precisa di attività muscolari finalizzate alla fonazione. Per farlo, Chang e colleghi hanno coinvolto cinque volontari a cui erano stati impiantati alcuni elettrodi nell’ambito di un trattamento terapeutico per l’epilessia. Usando una tecnica chiamata elettrocorticografia ad alta densità, hanno registrato l’attivazione delle diverse regioni della corteccia cerebrale dei volontari mentre pronunciavano alcune centinaia di frasi a voce alta. La seconda fase è stata dedicata alla trasformazione dei movimenti del tratto vocale decodificati nella prima fase in una voce sintetizzata.

Gli elettrodi usati nella sperimentazione (Credit UCSF)
Questo approccio, in realtà, è più contorto rispetto a quello di altri studi condotti in passato da altri gruppi di ricerca con lo stesso obiettivo, che hanno correlato direttamente
gli schemi di attivazione corticale ai suoni pronunciati. Ma l’idea di Chang e colleghi è stata premiata: la via indiretta permette di ottenere una distorsione acustica minore rispetto ad altre realizzazioni dello stesso tipo. Ciò è emerso in una serie di test in cui un gruppo di volontari è riuscito a riconoscere correttamente un centinaio di frasi sintetizzate dal dispositivo sulla base dell’addestramento precedente e quelle sintetizzate in tempo reale decodificando l’attività neurale di un soggetto a cui era richiesto di mimare l’articolazione di una frase senza pronunciarla
Complessivamente, il risultato è incoraggiante. Tuttavia,, come sottolineano in un articolo di commento pubblicato sullo stesso numero di “Nature” Chethan Pandarinath e Yahiaa Ali, del Georgia Institute of Technology di Atlanta, ci sono ancora problemi tecnologici da superare prima che il dispositivo di Chang e colleghi possa diventare un’interfaccia neurale da utilizzare in soggetti con un deficit del linguaggio dovuto a una patologia neurofunzionale.
La prima limitazione è che la comprensibilità del linguaggio sintetizzato dal dispositivo, per quanto soddisfacente, è ancora molto lontana da quella del linguaggio naturale. La seconda è che il dispositivo ha bisogno di un lungo periodo di addestramento con frasi pronunciate da una o più persone, e non potrebbe quindi essere applicato direttamente su soggetti che hanno perso la capacità di parlare. Rimediare a questi inconvenienti per arrivare a un dispositivo di utilità pratica sarà il compito di ricerche future. (red)
Fonte:
